In this post I will review the gradient descent algorithm that is commonly used to train the general class of models known as Boltzmann machines. Though the primary goal of the post is to supplement another post on restricted Boltzmann machines, I hope that those readers who are curious about how Boltzmann machines are trained, but have found it difficult to track down a complete or straight-forward derivation of the maximum likelihood learning algorithm for these models (as I have), will also find the post informative.
First, a little background: Boltzmann machines are stochastic neural networks that can be thought of as the probabilistic extension of the Hopfield network. The goal of the Boltzmann machine is to model a set of observed data in terms of a set of visible random variables  and a set of latent/unobserved random variables
and a set of latent/unobserved random variables  . Due to the relationship between Boltzmann machines and neural networks, the random variables are often are often referred to as “units.” The role of the visible units is to approximate the true distribution of the data, while the role of the latent variables it to extend the expressiveness of the model by capturing underlying features in the observed data. The latent variables are often referred to as hidden units, as they do not result directly from the observed data and are generally marginalized over to obtain the likelihood of the observed data, i.e.
. Due to the relationship between Boltzmann machines and neural networks, the random variables are often are often referred to as “units.” The role of the visible units is to approximate the true distribution of the data, while the role of the latent variables it to extend the expressiveness of the model by capturing underlying features in the observed data. The latent variables are often referred to as hidden units, as they do not result directly from the observed data and are generally marginalized over to obtain the likelihood of the observed data, i.e.
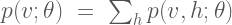 ,
,
where 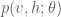 is the joint probability distribution over the visible and hidden units based on the current model parameters
is the joint probability distribution over the visible and hidden units based on the current model parameters 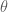 . The general Boltzmann machine defines through a set of weighted, symmetric connections between all visible and hidden units (but no connections from any unit to itself). The graphical model for the general Boltzmann machine is shown in Figure 1.
. The general Boltzmann machine defines through a set of weighted, symmetric connections between all visible and hidden units (but no connections from any unit to itself). The graphical model for the general Boltzmann machine is shown in Figure 1.

Figure 1: Graphical Model of the Boltzmann machine (biases not depicted).
Given the current state of the visible and hidden units, the overall configuration of the model network is described by a connectivity function  , parameterized by
, parameterized by 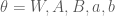 :
:
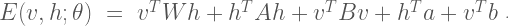
The parameter matrix  defines the connection strength between the visible and hidden units. The parameters
defines the connection strength between the visible and hidden units. The parameters  and
and 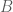 define the connection strength amongst hidden units and visible units, respectively. The model also includes a set of biases
define the connection strength amongst hidden units and visible units, respectively. The model also includes a set of biases  and
and 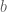 that capture offsets for each of the hidden and visible units.
that capture offsets for each of the hidden and visible units.
The Boltzmann machine has been used for years in field of statistical mechanics to model physical systems based on the principle of energy minimization. In the statistical mechanics, the connectivity function is often referred to the “energy function,” a term that is has also been standardized in the statistical learning literature. Note that the energy function returns a single scalar value for any configuration of the network parameters and random variable states.
Given the energy function, the Boltzmann machine models the joint probability of the visible and hidden unit states as a Boltzmann distribution:
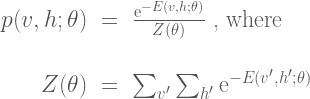
The partition function 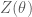 is a normalizing constant that is calculated by summing over all possible states of the network
is a normalizing constant that is calculated by summing over all possible states of the network  . Here we assume that all random variables take on discrete values, but the analogous derivation holds for continuous or mixed variable types by replacing the sums with integrals accordingly.
. Here we assume that all random variables take on discrete values, but the analogous derivation holds for continuous or mixed variable types by replacing the sums with integrals accordingly.
The common way to train the Boltzmann machine is to determine the parameters that maximize the likelihood of the observed data. To determine the parameters, we perform gradient descent on the log of the likelihood function (In order to simplify the notation in the remainder of the derivation, we do not include the explicit dependency on the parameters . To further simplify things, let’s also assume that we calculate the gradient of the likelihood based on a single observation.):

The gradient calculation is as follows:
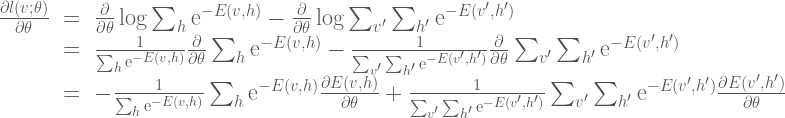
Here we can simplify the expression somewhat by noting that  , that
, that  , and also that
, and also that 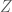 is a constant:
is a constant:
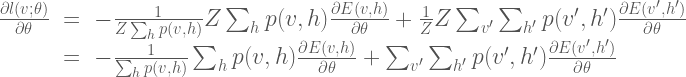
If we also note that  , and use the definition of conditional probability
, and use the definition of conditional probability 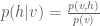 , we can further simplify the expression for the gradient:
, we can further simplify the expression for the gradient:

Here 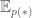 is the expected value under the distribution
is the expected value under the distribution  . Thus the gradient of the likelihood function is composed of two parts. The first part is expected gradient of the energy function with respect to the conditional distribution
. Thus the gradient of the likelihood function is composed of two parts. The first part is expected gradient of the energy function with respect to the conditional distribution  . The second part is expected gradient of the energy function with respect to the joint distribution over all variable states. However, calculating these expectations is generally infeasible for any realistically-sized model, as it involves summing over a huge number of possible states/configurations. The general approach for solving this problem is to use Markov Chain Monte Carlo (MCMC) to approximate these sums:
. The second part is expected gradient of the energy function with respect to the joint distribution over all variable states. However, calculating these expectations is generally infeasible for any realistically-sized model, as it involves summing over a huge number of possible states/configurations. The general approach for solving this problem is to use Markov Chain Monte Carlo (MCMC) to approximate these sums:

Here  is the sample average of samples drawn according to the process . The first term is calculated by taking the average value of the energy function gradient when the visible and hidden units are being driven by observed data samples. In practice, this first term is generally straightforward to calculate. Calculating the second term is generally more complicated and involves running a set of Markov chains until they reach the current model’s equilibrium distribution (i.e. via Gibbs sampling, Metropolis-Hastings, or the like), then taking the average energy function gradient based on those samples. See this post on MCMC methods for details. It turns out that there is a subclass of Boltzmann machines that, due to a restricted connectivity/energy function (specifically, the parameters
is the sample average of samples drawn according to the process . The first term is calculated by taking the average value of the energy function gradient when the visible and hidden units are being driven by observed data samples. In practice, this first term is generally straightforward to calculate. Calculating the second term is generally more complicated and involves running a set of Markov chains until they reach the current model’s equilibrium distribution (i.e. via Gibbs sampling, Metropolis-Hastings, or the like), then taking the average energy function gradient based on those samples. See this post on MCMC methods for details. It turns out that there is a subclass of Boltzmann machines that, due to a restricted connectivity/energy function (specifically, the parameters 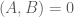 ), allow for efficient MCMC by way of blocked Gibbs sampling. These models, known as restricted Boltzman machines have become an important component for unsupervised pretraining in the field of deep learning and will be the focus of a related post.
), allow for efficient MCMC by way of blocked Gibbs sampling. These models, known as restricted Boltzman machines have become an important component for unsupervised pretraining in the field of deep learning and will be the focus of a related post.

