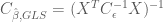Blog Archives
Derivation: Error Backpropagation & Gradient Descent for Neural Networks
The material in this post has been migraged with python implementations to my github pages website.
Derivation: The Covariance Matrix of an OLS Estimator (and applications to GLS)
We showed in an earlier post that for the linear regression model
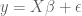
the optimal Ordinary Least Squares (OLS) estimator for model parameters 
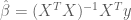
However, because independent variables 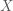
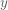

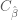
![C_{\hat \beta} = E[(\hat \beta - \beta)(\hat \beta - \beta)^T]](https://s0.wp.com/latex.php?latex=C_%7B%5Chat+%5Cbeta%7D+%3D+E%5B%28%5Chat+%5Cbeta+-+%5Cbeta%29%28%5Chat+%5Cbeta+-+%5Cbeta%29%5ET%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
where, ![E[*]](https://s0.wp.com/latex.php?latex=E%5B%2A%5D&bg=ffffff&fg=4e4e4e&s=-1&c=20201002)
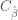

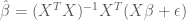
where we use the fact that
It follows that

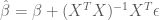
and therefore
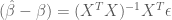
Now following the original definition for
![= E[(X^TX)^{-1}X^T\epsilon((X^TX)^{-1}X^T \epsilon)^T]](https://s0.wp.com/latex.php?latex=%3D+E%5B%28X%5ETX%29%5E%7B-1%7DX%5ET%5Cepsilon%28%28X%5ETX%29%5E%7B-1%7DX%5ET+%5Cepsilon%29%5ET%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![= E[(X^TX)^{-1}X^T\epsilon \epsilon^T X(X^TX)^{-1}]](https://s0.wp.com/latex.php?latex=%3D+E%5B%28X%5ETX%29%5E%7B-1%7DX%5ET%5Cepsilon+%5Cepsilon%5ET+X%28X%5ETX%29%5E%7B-1%7D%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
where we take advantage of 


![C_{\hat \beta} = (X^TX)^{-1}X^T E[\epsilon \epsilon^T] X(X^TX)^{-1}](https://s0.wp.com/latex.php?latex=C_%7B%5Chat+%5Cbeta%7D+%3D+%28X%5ETX%29%5E%7B-1%7DX%5ET+E%5B%5Cepsilon+%5Cepsilon%5ET%5D+X%28X%5ETX%29%5E%7B-1%7D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
where ![E[\epsilon \epsilon^T]](https://s0.wp.com/latex.php?latex=E%5B%5Cepsilon+%5Cepsilon%5ET%5D&bg=ffffff&fg=4e4e4e&s=-1&c=20201002)


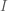


which simplifies to
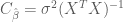
A further simplifying assumption made by OLS that is often made is that 


Applying the derivation results to Generalized Least Squares
Notice that the expression for the OLS estimator covariance is equal to first inverse term in the expression for the OLS estimator. Identitying the covariance for the OLS estimator in this way gives a helpful heuristic to easily identify the covariance of related estimators that do not make the simplifying assumptions about the covariance that are made in OLS. For instance in Generalized Least Squares (GLS), it is possible for the noise terms to co-vary. The covariance is represented as a noise covariance matrix 
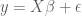
where ![E[\epsilon | X] = 0; Var[\epsilon | X] = C_{\epsilon}](https://s0.wp.com/latex.php?latex=E%5B%5Cepsilon+%7C+X%5D+%3D+0%3B+Var%5B%5Cepsilon+%7C+X%5D+%3D+C_%7B%5Cepsilon%7D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
In otherwords, under GLS, the noise terms have zero mean, and covariance 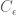
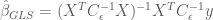
Notice the similarity between the GLS and OLS estimators. The only difference is that in GLS, the solution for the parameters is scaled by the inverse of the noise covariance. And, in a similar fashion to the OLS estimator, the covariance for the GLS estimator is first term in the product that defines the GLS estimator: