fMRI In Neuroscience: Efficiency of Event-related Experiment Designs
Event-related fMRI experiments are used to detect selectivity in the brain to stimuli presented over short durations. An event is generally modeled as an impulse function that occurs at the onset of the stimulus in question. Event-related designs are flexible in that many different classes of stimuli can be intermixed. These designs can minimize confounding behavioral effects due to subject adaptation or expectation. Furthermore, stimulus onsets can be modeled at frequencies that are shorter than the repetition time (TR) of the scanner. However, given such flexibility in design and modeling, how does one determine the schedule for presenting a series of stimuli? Do we space out stimulus onsets periodically across a scan period? Or do we randomize stimulus onsets? Furthermore what is the logic for or against either approach? Which approach is more efficient for gaining incite into the selectivity in the brain?
Simulating Two fMRI Experiments: Periodic and Random Stimulus Onsets
To get a better understanding of the problem of choosing efficient experiment design, let’s simulate two simple fMRI experiments. In the first experiment, a stimulus is presented periodically 20 times, once every 4 seconds, for a run of 80 seconds in duration. We then simulate a noiseless BOLD signal evoked in a voxel with a known HRF. In the second experiment, we simulate the noiseless BOLD signal evoked by 20 stimulus onsets that occur at random times over the course of the 80 second run duration. The code for simulating the signals and displaying output are shown below:
rand('seed',12345);
randn('seed',12345);
TR = 1 % REPETITION TIME
t = 1:TR:20; % MEASUREMENTS
h = gampdf(t,6) + -.5*gampdf(t,10); % ACTUAL HRF
h = h/max(h); % SCALE TO MAX OF 1
% SOME CONSTANTS...
trPerStim = 4; % # TR PER STIMULUS FOR PERIODIC EXERIMENT
nRepeat = 20; % # OF TOTAL STIMULI SHOWN
nTRs = trPerStim*nRepeat
stimulusTrain0 = zeros(1,nTRs);
beta = 3; % SELECTIVITY/HRF GAIN
% SET UP TWO DIFFERENT STIMULUS PARADIGM...
% A. PERIODIC, NON-RANDOM STIMULUS ONSET TIMES
D_periodic = stimulusTrain0;
D_periodic(1:trPerStim:trPerStim*nRepeat) = 1;
% UNDERLYING MODEL FOR (A)
X_periodic = conv2(D_periodic,h);
X_periodic = X_periodic(1:nTRs);
y_periodic = X_periodic*beta;
% B. RANDOM, UNIFORMLY-DISTRIBUTED STIMULUS ONSET TIMES
D_random = stimulusTrain0;
randIdx = randperm(numel(stimulusTrain0)-5);
D_random(randIdx(1:nRepeat)) = 1;
% UNDERLYING MODEL FOR (B)
X_random = conv2(D_random,h);
X_random = X_random(1:nTRs);
y_random = X_random*beta;
% DISPLAY STIMULUS ONSETS AND EVOKED RESPONSES
% FOR EACH EXPERIMENT
figure
subplot(121)
stem(D_periodic,'k');
hold on;
plot(y_periodic,'r','linewidth',2);
xlabel('Time (TR)');
title(sprintf('Responses Evoked by\nPeriodic Stimulus Onset\nVariance=%1.2f',var(y_periodic)))
subplot(122)
stem(D_random,'k');
hold on;
plot(y_random,'r','linewidth',2);
xlabel('Time (TR)');
title(sprintf('Responses Evoked by\nRandom Stimulus Onset\nVariance=%1.2f',var(y_random)))

BOLD signals evoked by periodic (left) and random (right) stimulus onsets.
The black stick functions in the simulation output indicate the stimulus onsets and each red function is the simulated noiseless BOLD signal to those stimuli. The first thing to notice is the dramatically different variances of the BOLD signals evoked for the two stimulus presentation schedules. For the periodic stimuli, the BOLD signal quickly saturates, then oscillates around an effective baseline activation. The estimated variance of the periodic-based signal is 0.18. In contrast, the signal evoked by the random stimulus presentation schedule varies wildly, reaching a maximum amplitude that is roughly 2.5 times as large the maximum amplitude of the signal evoked by periodic stimuli. The estimated variance of the signal evoked by the random stimuli is 7.4, roughly 40 times the variance of the signal evoked by the periodic stimulus.
So which stimulus schedule allows us to better estimate the HRF and, more importantly, the amplitude of the HRF, as it is the amplitude that is the common proxy for voxel selectivity/activation? Below we repeat the above experiment 50 times. However, instead of simulating noiseless BOLD responses, we introduce 50 distinct, uncorrelated noise conditions, and from the simulated noisy responses, we estimate the HRF using an FIR basis set for each repeated trial. We then compare the estimated HRFs across the 50 trials for the periodic and random stimulus presentation schedules. Note that for each trial, the noise is exactly the same for the two stimulus presentation schedules. Further, we simulate a selectivity/tuning gain of 3 times the maximum HRF amplitude and assume that the HRF to be estimated is 16 TRs/seconds in length. The simulation and output are below:
%% SIMULATE MULTIPLE TRIALS OF EACH EXPERIMENT
%% AND ESTIMATE THE HRF FOR EACH
%% (ASSUME THE VARIABLES DEFINED ABOVE ARE IN WORKSPACE)
% CREATE AN FIR DESIGN MATRIX
% FOR EACH EXPERIMENT
hrfLen = 16; % WE ASSUME TO-BE-ESTIMATED HRF IS 16 TRS LONG
% CREATE FIR DESIGN MATRIX FOR THE PERIODIC STIMULI
X_FIR_periodic = zeros(nTRs,hrfLen);
onsets = find(D_periodic);
idxCols = 1:hrfLen;
for jO = 1:numel(onsets)
idxRows = onsets(jO):onsets(jO)+hrfLen-1;
for kR = 1:numel(idxRows);
X_FIR_periodic(idxRows(kR),idxCols(kR)) = 1;
end
end
X_FIR_periodic = X_FIR_periodic(1:nTRs,:);
% CREATE FIR DESIGN MATRIX FOR THE RANDOM STIMULI
X_FIR_random = zeros(nTRs,hrfLen);
onsets = find(D_random);
idxCols = 1:hrfLen;
for jO = 1:numel(onsets)
idxRows = onsets(jO):onsets(jO)+hrfLen-1;
for kR = 1:numel(idxRows);
X_FIR_random(idxRows(kR),idxCols(kR)) = 1;
end
end
X_FIR_random = X_FIR_random(1:nTRs,:);
% SIMULATE AND ESTIMATE HRF WEIGHTS VIA OLS
nTrials = 50;
% CREATE NOISE TO ADD TO SIGNALS
% NOTE: SAME NOISE CONDITIONS FOR BOTH EXPERIMENTS
noiseSTD = beta*2;
noise = bsxfun(@times,randn(nTrials,numel(X_periodic)),noiseSTD);
%% ESTIMATE HRF FROM PERIODIC STIMULUS TRIALS
beta_periodic = zeros(nTrials,hrfLen);
for iT = 1:nTrials
y = y_periodic + noise(iT,:);
beta_periodic(iT,:) = X_FIR_periodic\y';
end
% CALCULATE MEAN AND STANDARD ERROR OF HRF ESTIMATES
beta_periodic_mean = mean(beta_periodic);
beta_periodic_se = std(beta_periodic)/sqrt(nTrials);
%% ESTIMATE HRF FROM RANDOM STIMULUS TRIALS
beta_random = zeros(nTrials,hrfLen);
for iT = 1:nTrials
y = y_random + noise(iT,:);
beta_random(iT,:) = X_FIR_random\y';
end
% CALCULATE MEAN AND STANDARD ERROR OF HRF ESTIMATES
beta_random_mean = mean(beta_random);
beta_random_se = std(beta_random)/sqrt(nTrials);
% DISPLAY HRF ESTIMATES
figure
% ...FOR THE PERIODIC STIMULI
subplot(121);
hold on;
h0 = plot(h*beta,'k')
h1 = plot(beta_periodic_mean,'linewidth',2);
h2 = plot(beta_periodic_mean+beta_periodic_se,'r','linewidth',2);
plot(beta_periodic_mean-beta_periodic_se,'r','linewidth',2);
xlabel('Time (TR)')
legend([h0, h1,h2],'Actual HRF','Average \beta_{periodic}','Standard Error')
title('Periodic HRF Estimate')
% ...FOR THE RANDOMLY-PRESENTED STIMULI
subplot(122);
hold on;
h0 = plot(h*beta,'k');
h1 = plot(beta_random_mean,'linewidth',2);
h2 = plot(beta_random_mean+beta_random_se,'r','linewidth',2);
plot(beta_random_mean-beta_random_se,'r','linewidth',2);
xlabel('Time (TR)')
legend([h0,h1,h2],'Actual HRF','Average \beta_{random}','Standard Error')
title('Random HRF Estimate')

Estimated HRFs from 50 trials of periodic (left) and random (right) stimulus schedules
In the simulation outputs, the average HRF for the random stimulus presentation (right) closely follows the actual HRF tuning. Also, there is little variability of the HRF estimates, as is indicated by the small standard error estimates for each time points. As well, the selectivity/gain term is accurately recovered, giving a mean HRF with nearly the same amplitude as the underlying model. In contrast, the HRF estimated from the periodic-based experiment is much more variable, as indicated by the large standard error estimates. Such variability in the estimates of the HRF reduce our confidence in the estimate for any single trial. Additionally, the scale of the mean HRF estimate is off by nearly 30% of the actual value.
From these results, it is obvious that the random stimulus presentation rate gives rise to more accurate, and less variable estimates of the HRF function. What may not be so obvious is why this is the case, as there were the same number of stimuli and the same number of signal measurements in each experiment. To get a better understanding of why this is occurring, let’s refer back to the variances of the evoked noiseless signals. These are the signals that are underlying the noisy signals used to estimate the HRF. When noise is added it impedes the detection of the underlying trends that are useful for estimating the HRF. Thus it is important that the variance of the underlying signal is large compared to the noise so that the signal can be detected.
For the periodic stimulus presentation schedule, we saw that the variation in the BOLD signal was much smaller than the variation in the BOLD signals evoked during the randomly-presented stimuli. Thus the signal evoked by random stimulus schedule provide a better characterization of the underlying signal in the presence of the same amount of noise, and thus provide more information to estimate the HRF. With this in mind we can think of maximizing the efficiency of the an experiment design as maximizing the variance of the BOLD signals evoked by the experiment.
An Alternative Perspective: The Frequency Power Spectrum
Another helpful interpretation is based on a signal processing perspective. If we assume that neural activity is directly correspondent with the onset of a stimulus event, then we can interpret the train of stimulus onsets as a direct signal of the evoked neural activity. Furthermore, we can interpret the HRF as a low-pass-filter that acts to “smooth” the available neural signal in time. Each of these signals–the neural/stimulus signal and the HRF filtering signal–has with it an associated power spectrum. The power spectrum for a signal captures the amount of power per unit time that the signal has as a particular frequency 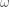
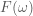
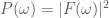
Below, we use Matlab’s 
%% POWER SPECTRUM ANALYSES
%% (ASSUME THE VARIABLES DEFINED ABOVE ARE IN WORKSPACE)
% MAKE SURE WE PAD SUFFICIENTLY
% FOR CIRCULAR CONVOLUTION
N = 2^nextpow2(nTRs + numel(h)-1);
nUnique = ceil(1+N/2); % TAKE ONLY POSITIVE SPECTRA
% CALCULATE POWER SPECTRUM FOR PERIODIC STIMULI EXPERIMENT
ft_D_periodic = fft(D_periodic,N)/N; % DFT
P_D_periodic = abs(ft_D_periodic).^2; % POWER
P_D_periodic = 2*P_D_periodic(2:nUnique-1); % REMOVE ZEROTH & NYQUIST
% CALCULATE POWER SPECTRUM FOR RANDOM STIMULI EXPERIMENT
ft_D_random = fft(D_random,N)/N; % DFT
P_D_random = abs(ft_D_random).^2; % POWER
P_D_random = 2*P_D_random(2:nUnique-1); % REMOVE ZEROTH & NYQUIST
% CALCULATE POWER SPECTRUM OF HRF
ft_h = fft(h,N)/N; % DFT
P_h = abs(ft_h).^2; % POWER
P_h = 2*P_h(2:nUnique-1); % REMOVE ZEROTH & NYQUIST
% CREATE A FREQUENCY SPACE FOR PLOTTING
F = 1/N*[1:N/2-1];
% DISPLAY STIMULI POWER SPECTRA
figure
subplot(131)
hhd = plot(F,P_D_periodic,'b','linewidth',2);
axis square; hold on;
hhr = plot(F,P_D_random,'g','linewidth',2);
xlim([0 .3]); xlabel('Frequency (Hz)');
set(gca,'Ytick',[]); ylabel('Magnitude');
legend([hhd,hhr],'Periodic','Random')
title('Stimulus Power, P_{stim}')
% DISPLAY HRF POWER SPECTRUM
subplot(132)
plot(F,P_h,'r','linewidth',2);
axis square
xlim([0 .3]); xlabel('Frequency (Hz)');
set(gca,'Ytick',[]); ylabel('Magnitude');
title('HRF Power, P_{HRF}')
% DISPLAY EVOKED SIGNAL POWER SPECTRA
subplot(133)
hhd = plot(F,P_D_periodic.*P_h,'b','linewidth',2);
hold on;
hhr = plot(F,P_D_random.*P_h,'g','linewidth',2);
axis square
xlim([0 .3]); xlabel('Frequency (Hz)');
set(gca,'Ytick',[]); ylabel('Magnitude');
legend([hhd,hhr],'Periodic','Random')
title('Signal Power, P_{stim}.*P_{HRF}')

Power spectrum of neural/stimulus (left), HRF (center), and evoked BOLD (right) signals
On the left of the output we see the power spectra for the stimulus signals. The blue line corresponds to the spectrum for the periodic stimuli, and the green line the spectrum for the randomly-presented stimuli. The large peak in the blue spectrum corresponds to the majority of the stimulus power at 0.25 Hz for the periodic stimuli, as this the fundamental frequency of the periodic stimulus presentation (i.e. every 4 seconds). However, there is little power at any other stimulus frequencies. In contrast the green spectrum indicates that the random stimulus presentation has power at multiple frequencies.
If we interpret the HRF as a filter, then we can think of the HRF power spectrum as modulating the power spectrum of the neural signals to produce the power of the evoked BOLD signals. The power spectrum for the HRF is plotted in red in the center plot. Notice how a majority of the power for the HRF is at frequencies less than 0.1 Hz, and there is very little power at frequencies above 0.2 Hz. If the neural signal power is modulated by the HRF signal power, we see that there is little resultant power in the BOLD signals evoked by periodic stimulus presentation (blue spectrum in the right plot). In contrast, because the power for the neural signals evoked by random stimuli are spread across the frequency domain, there are a number of frequencies that overlap with those frequencies for which the HRF also has power. Thus after modulating neural/stimulus power with the HRF power, the spectrum of the BOLD signals evoked by the randomly-presented stimuli have much more power across the relevant frequency spectrum than those evoked by the periodic stimuli. This is indicated by the larger area under the green curve in the right plot.
Using the signal processing perspective allows us to directly gain perspective on the limitations of a particular experiment design which are rooted in the frequency spectrum of the HRF. Therefore, another way we can think of maximizing the efficiency of an experimental design is maximizing the amount of power in the resulting evoked BOLD responses.
Yet Another Perspective Based in Statistics: Efficiency Metric
Taking a statistics-based approach leads to a formal definition of efficiency, and further, a nice metric for testing the efficiency of an experimental design. Recall that when determining the shape of the HRF, a common approach is to use the GLM model
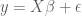
Here 

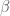


Because fMRI data are a continuous time series, the underlying noise 
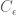
For a known or estimated noise covariance, the Maximum Likelihood Estimator (MLE) for the model parameters 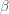

Because the ML estimator of the HRF is a linear combination of the design matrix 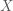
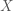
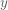
A formal metric for efficiency of a least-squares estimator is directly related to the variance of the estimator. The efficiency is defined to be the inverse of the sum of the estimator variances. An estimator that has a large sum of variances will have a low efficiency, and vice versa. But how do we obtain the values of the variances for the estimator? The variances can be recovered from the diagonal elements of the estimator covariance matrix 
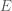
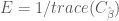
In earlier post we found that the covariance matrix
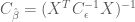
Thus the efficiency for the HRF estimator is
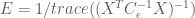
Here we see that the efficiency depends only on the known noise covariance (or an estimate of it), and the design matrix used in the model, but not the shape of the HRF. In general the noise covariance is out of the experimenter’s control (but see the take-homes below ), and must be dealt with post hoc. However, because the design matrix is directly related to the experimental design, the above expression gives a direct way to test the efficiency of experimental designs before they are ever used!
In the simulations above, the noise processes are drawn from an independent multivariate Gaussian distribution, therefore the noise covariance is equal to the identity (i.e. uncorrelated). We also estimated the HRF using the FIR basis set, thus our model design matrix was 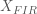
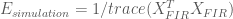
Below we calculate the efficiency for the FIR estimates under the simulated experiments with periodic and random stimulus presentation designs.
%% ESTIMATE DESIGN EFFICIENCY
%% (ASSUME THE VARIABLES DEFINED ABOVE ARE IN WORKSPACE)
% CALCULATE EFFICIENCY OF PERIODIC EXPERIMENT
E_periodic = 1/trace(pinv(X_FIR_periodic'*X_FIR_periodic));
% CALCULATE EFFICIENCY OF RANDOM EXPERIMENT
E_random = 1/trace(pinv(X_FIR_random'*X_FIR_random));
% DISPLAY EFFICIENCY ESTIMATES
figure
bar([E_periodic,E_random]);
set(gca,'XTick',[1,2],'XTickLabel',{'E_periodic','E_random'});
title('Efficiency of Experimental Designs');
colormap hot;

Estimated efficiency for simulated periodic (left) and random (right) stimulus schedules.
Here we see that the efficiency metric does indeed indicate that the randomly-presented stimulus paradigm is far more efficient than the periodically-presented paradigm.
Wrapping Up
In this post we addressed the efficiency of an fMRI experiment design. A few take-homes from the discussion are:
- Randomize stimulus onset times. These onset times should take into account the low-pass characteristics (i.e. the power spectrum) of the HRF.
- Try to model selectivity to events that occur close in time. The reason for this is that noise covariances in fMRI are highly non-stationary. There are many sources of low-frequency physiological noise such as breathing, pulse, blood pressure, etc, all of which dramatically effect the noise in the fMRI timecourses. Thus any estimate of noise covariances from data recorded far apart in time will likely be erroneous.
- Check an experimental design against other candidate designs using the Efficiency metric.
Above there is mention of the effects of low-frequency physiological noise. Until now, our simulations have assumed that all noise is independent in time, greatly simplifying the picture of estimating HRFs and corresponding selectivity. However, in a later post we’ll address how to deal with more realistic time courses that are heavily influenced by sources of physiological noise. Additionally, we’ll tackle how to go about estimating the noise covariance 
Posted on January 14, 2013, in fMRI, Regression, Simulations, Statistics and tagged BOLD Power Spectrum, Covariance Matrix, fMRI, fMRI Design Efficiency, General Linear Model, Generalize Least Squares, GLM, GLS, Power Spectrum. Bookmark the permalink. Leave a comment.

Leave a comment
Comments 0