MCMC: Hamiltonian Monte Carlo (a.k.a. Hybrid Monte Carlo)
The random-walk behavior of many Markov Chain Monte Carlo (MCMC) algorithms makes Markov chain convergence to a target stationary distribution 
First off, a brief physics lesson in Hamiltonian dynamics
Before we can develop Hamiltonian Monte Carlo, we need to become familiar with the concept of Hamiltonian dynamics. Hamiltonian dynamics is one way that physicists describe how objects move throughout a system. Hamiltonian dynamics describe an object’s motion in terms of its location 



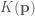


Hamiltonian dynamics describe how kinetic energy is converted to potential energy (and vice versa) as an object moves throughout a system in time. This description is implemented quantitatively via a set of differential equations known as the Hamiltonian equations:


Therefore, if we have expressions for 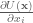
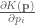


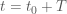
Simulating Hamiltonian dynamics — the Leap Frog Method
The Hamiltonian equations describe an object’s motion in time, which is a continuous variable. In order to simulate Hamiltonian dynamics numerically on a computer, it is necessary to approximate the Hamiltonian equations by discretizing time. This is done by splitting the interval 

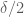
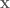

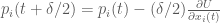
2. Take a full step in time to update the position variable
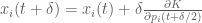
3. Take the remaining half step in time to finish updating the momentum variable

The Leap Fog method can be run for 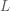

Example 1: Simulating Hamiltonian dynamics of an harmonic oscillator
Imagine a ball with mass equal to one is attached to a horizontally-oriented spring. The spring exerts a force on the ball equal to

which works to restore the ball’s position to the equilibrium position of the spring at 
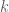


In addition, the kinetic energy an object with mass 


if the object’s mass is equal to one, like the ball this example. Notice that we now have in hand the expressions for both 
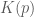
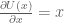
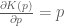
Therefore one iteration the Leap Frog algorithm for simulating Hamiltonian dynamics in this system is:
1.
2. 

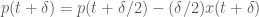
We simulate the dynamics of the spring-mass system described using the Leap Frog method in Matlab below (if the graph is not animated, try clicking on it to open up the linked .gif). The left bar in the bottom left subpanel of the simulation output demonstrates the trade-off between potential and kinetic energy described by Hamiltonian dynamics. The cyan portion of the bar is the proportion of the Hamiltonian contributed by the potential energy 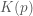

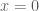

Simple example of Hamiltonian Dynamics: 1D Harmonic Oscillator (Click to see animated)
You may also notice that the value of the Hamiltonian 
% EXAMPLE 1: SIMULATING HAMILTONIAN DYNAMICS
% OF HARMONIC OSCILLATOR
% STEP SIZE
delta = 0.1;
% # LEAP FROG
L = 70;
% DEFINE KINETIC ENERGY FUNCTION
K = inline('p^2/2','p');
% DEFINE POTENTIAL ENERGY FUNCTION FOR SPRING (K =1)
U = inline('1/2*x^2','x');
% DEFINE GRADIENT OF POTENTIAL ENERGY
dU = inline('x','x');
% INITIAL CONDITIONS
x0 = -4; % POSTIION
p0 = 1; % MOMENTUM
figure
%% SIMULATE HAMILTONIAN DYNAMICS WITH LEAPFROG METHOD
% FIRST HALF STEP FOR MOMENTUM
pStep = p0 - delta/2*dU(x0)';
% FIRST FULL STEP FOR POSITION/SAMPLE
xStep = x0 + delta*pStep;
% FULL STEPS
for jL = 1:L-1
% UPDATE MOMENTUM
pStep = pStep - delta*dU(xStep);
% UPDATE POSITION
xStep = xStep + delta*pStep;
% UPDATE DISPLAYS
subplot(211), cla
hold on;
xx = linspace(-6,xStep,1000);
plot(xx,sin(6*linspace(0,2*pi,1000)),'k-');
plot(xStep+.5,0,'bo','Linewidth',20)
xlim([-6 6]);ylim([-1 1])
hold off;
title('Harmonic Oscillator')
subplot(223), cla
b = bar([U(xStep),K(pStep);0,U(xStep)+K(pStep)],'stacked');
set(gca,'xTickLabel',{'U+K','H'})
ylim([0 10]);
title('Energy')
subplot(224);
plot(xStep,pStep,'ko','Linewidth',20);
xlim([-6 6]); ylim([-6 6]); axis square
xlabel('x'); ylabel('p');
title('Phase Space')
pause(.1)
end
% (LAST HALF STEP FOR MOMENTUM)
pStep = pStep - delta/2*dU(xStep);
Hamiltonian dynamics and the target distribution 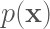
Now that we have a better understanding of what Hamiltonian dynamics are and how they can be simulated, let’s now discuss how we can use Hamiltonian dynamics for MCMC. The main idea behind Hamiltonian/Hibrid Monte Carlo is to develop a Hamiltonian function 


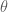

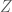

Therefore the canoncial distribution for the Hamiltonian dynamics energy function is
![p(\bold x,\bold p) \propto e^{-H(\bold x,\bold p)} \\ = e^{-[U(\bold x) - K(\bold p)]} \\ = e^{-U(\bold x)}e^{-K(\bold p)} \\ \propto p(\bold x)p(\bold p)](https://s0.wp.com/latex.php?latex=p%28%5Cbold+x%2C%5Cbold+p%29+%5Cpropto+e%5E%7B-H%28%5Cbold+x%2C%5Cbold+p%29%7D+%5C%5C+%3D+e%5E%7B-%5BU%28%5Cbold+x%29+-+K%28%5Cbold+p%29%5D%7D+%5C%5C+%3D+e%5E%7B-U%28%5Cbold+x%29%7De%5E%7B-K%28%5Cbold+p%29%7D+%5C%5C+%5Cpropto+p%28%5Cbold+x%29p%28%5Cbold+p%29&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Here we see that joint (canonical) distribution for

Note that this is equivalent to having a quadratic potential energy term in the Hamiltonian:

Recall that this is is the exact quadratic kinetic energy function (albeit in 1D) used in the harmonic oscillator example above. This is a convenient choice for the kinetic energy function as all partial derivatives are easy to compute. Now that we have defined a kinetic energy function, all we have to do is find a potential energy function 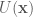
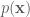

If we can calculate 
Hamiltonian Monte Carlo
In HMC we use Hamiltonian dynamics as a proposal function for a Markov Chain in order to explore the target (canonical) density ![[\bold x_0, \bold p_0]](https://s0.wp.com/latex.php?latex=%5B%5Cbold+x_0%2C+%5Cbold+p_0%5D&bg=ffffff&fg=4e4e4e&s=-1&c=20201002)

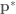
![p(\bold x^*, \bold p^*) \propto e^{-[U(\bold x^*) + K{\bold p^*}]}](https://s0.wp.com/latex.php?latex=p%28%5Cbold+x%5E%2A%2C+%5Cbold+p%5E%2A%29+%5Cpropto+e%5E%7B-%5BU%28%5Cbold+x%5E%2A%29+%2B+K%7B%5Cbold+p%5E%2A%7D%5D%7D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
is greater than probability of the state prior to the Hamiltonian dynamics
![p(\bold x_0,\bold p_0) \propto e^{-[U(\bold x^{(t-1)}), K(\bold p^{(t-1)})]}](https://s0.wp.com/latex.php?latex=p%28%5Cbold+x_0%2C%5Cbold+p_0%29+%5Cpropto+e%5E%7B-%5BU%28%5Cbold+x%5E%7B%28t-1%29%7D%29%2C+K%28%5Cbold+p%5E%7B%28t-1%29%7D%29%5D%7D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
then the proposed state is accepted, otherwise, the proposed state is accepted randomly. If the state is rejected, the next state of the Markov chain is set as the state at 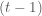


- set
- generate an initial position state
- repeat until



set

– sample a new initial momentum variable from the momentum canonical distribution

– set
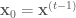
– run Leap Frog algorithm starting at ![[\bold x_0, \bold p_0]](https://s0.wp.com/latex.php?latex=%5B%5Cbold+x_0%2C+%5Cbold+p_0%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)



– calculate the Metropolis acceptance probability:

– draw a random number 

if 
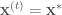
else set

In the next example we implement HMC to sample from a multivariate target distribution that we have sampled from previously using multi-variate Metropolis-Hastings, the bivariate Normal. We also qualitatively compare the sampling dynamics of HMC to multivariate Metropolis-Hastings for the sampling the same distribution.
Example 2: Hamiltonian Monte for sampling a Bivariate Normal distribution
As a reminder, the target distribution
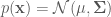
with mean
![\mu = [\mu_1,\mu_2]= [0, 0]](https://s0.wp.com/latex.php?latex=%5Cmu+%3D+%5B%5Cmu_1%2C%5Cmu_2%5D%3D+%5B0%2C+0%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
and covariance

In order to sample from

Recall that the target potential energy function can be defined from the canonical form as

If we take the negative log of the Normal distribution outline above, this defines the following potential energy function:
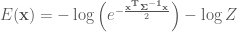
Where 
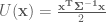
with partial derivatives
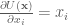
Using these expressions for the potential energy and its partial derivatives, we implement HMC for sampling from the bivariate Normal in Matlab:

Hybrid Monte Carlo Samples from bivariate Normal target distribution
In the graph above we display HMC samples of the target distribution, starting from an initial position very far from the mean of the target. We can see that HMC rapidly approaches areas of high density under the target distribution. We compare these samples with samples drawn using the Metropolis-Hastings (MH) algorithm below. The MH algorithm converges much slower than HMC, and consecutive samples have much higher autocorrelation than samples drawn using HMC.

Metropolis-Hasting (MH) samples of the same target distribution. Autocorrelation is evident. HMC is much more efficient than MH.
The Matlab code for the HMC sampler:
% EXAMPLE 2: HYBRID MONTE CARLO SAMPLING -- BIVARIATE NORMAL
rand('seed',12345);
randn('seed',12345);
% STEP SIZE
delta = 0.3;
nSamples = 1000;
L = 20;
% DEFINE POTENTIAL ENERGY FUNCTION
U = inline('transp(x)*inv([1,.8;.8,1])*x','x');
% DEFINE GRADIENT OF POTENTIAL ENERGY
dU = inline('transp(x)*inv([1,.8;.8,1])','x');
% DEFINE KINETIC ENERGY FUNCTION
K = inline('sum((transp(p)*p))/2','p');
% INITIAL STATE
x = zeros(2,nSamples);
x0 = [0;6];
x(:,1) = x0;
t = 1;
while t < nSamples
t = t + 1;
% SAMPLE RANDOM MOMENTUM
p0 = randn(2,1);
%% SIMULATE HAMILTONIAN DYNAMICS
% FIRST 1/2 STEP OF MOMENTUM
pStar = p0 - delta/2*dU(x(:,t-1))';
% FIRST FULL STEP FOR POSITION/SAMPLE
xStar = x(:,t-1) + delta*pStar;
% FULL STEPS
for jL = 1:L-1
% MOMENTUM
pStar = pStar - delta*dU(xStar)';
% POSITION/SAMPLE
xStar = xStar + delta*pStar;
end
% LAST HALP STEP
pStar = pStar - delta/2*dU(xStar)';
% COULD NEGATE MOMENTUM HERE TO LEAVE
% THE PROPOSAL DISTRIBUTION SYMMETRIC.
% HOWEVER WE THROW THIS AWAY FOR NEXT
% SAMPLE, SO IT DOESN'T MATTER
% EVALUATE ENERGIES AT
% START AND END OF TRAJECTORY
U0 = U(x(:,t-1));
UStar = U(xStar);
K0 = K(p0);
KStar = K(pStar);
% ACCEPTANCE/REJECTION CRITERION
alpha = min(1,exp((U0 + K0) - (UStar + KStar)));
u = rand;
if u < alpha
x(:,t) = xStar;
else
x(:,t) = x(:,t-1);
end
end
% DISPLAY
figure
scatter(x(1,:),x(2,:),'k.'); hold on;
plot(x(1,1:50),x(2,1:50),'ro-','Linewidth',2);
xlim([-6 6]); ylim([-6 6]);
legend({'Samples','1st 50 States'},'Location','Northwest')
title('Hamiltonian Monte Carlo')
Wrapping up
In this post we introduced the Hamiltonian/Hybrid Monte Carlo algorithm for more efficient MCMC sampling. The HMC algorithm is extremely powerful for sampling distributions that can be represented terms of a potential energy function and its partial derivatives. Despite the efficiency and elegance of HMC, it is an underrepresented sampling routine in the literature. This may be due to the popularity of simpler algorithms such as Gibbs sampling or Metropolis-Hastings, or perhaps due to the fact that one must select hyperparameters such as the number of Leap Frog steps and Leap Frog step size when using HMC. However, recent research has provided effective heuristics such as adapting the Leap Frog step size in order to maintain a constant Metropolis rejection rate, which facilitate the use of HMC for general applications.
Posted on November 18, 2012, in Algorithms, Sampling, Simulations and tagged Auxiliary Variables, Canonical Distribution, Energy Drift, Hamiltonian Dynamics, Hamiltonian Monte Carlo, Hybrid Monte Carlo, Markov Chain Monte Carlo, MCMC, Partition Function, Phase Space, Stationary Distribution. Bookmark the permalink. 12 Comments.

I believe there is an error in your HMC sampler. Your code has `U0 = U(x0)`. However, x0 is never updated to be the latest sample in your loop. The correct line of code should be `U0 = U(x(:, t-1))`. Alternatively, you could add `x0 = x(:, t-1)` after `t = t + 1`. Thank you for the great tutorial.
Prajit, you’re correct, the code was missing the updated sample states at each iteration. The code has been updated. Thanks!
Reblogged this on 木秀于林.
Beautiful tutorial! Very well explained.
Reblogged this on Solving one problem at a time and commented:
Aesome blog post! Want to use HMC in my research
Hello, many many thanks for such a nice short tutorial on HMC… I am a newbie in HMC… I want to know how sampling from a assymetric distribution can be done using HMC… I am talking about distributions like gamma, inverse gaussian etc which we frequently encounter in Bayesian Machine Learning models. Like for linear regression if I want to estimate the posterior of noise variance which is generally endowed with inverse gamma prior… It will be very helpful if you can enlighten me regarding this… Thanks in advance…
Reblogged this on Flaw // 破绽 and commented:
Still reading…..
Thanks for the awesome post. Reblogged to the 破绽//Flaw.
Very nice, useful and effective explained. Actually, the algorithm is really sensitive to hyper parameters. Is there any effective solution?
Pingback: A Gentle Introduction to Markov Chain Monte Carlo (MCMC) « The Clever Machine
Pingback: MCMC: Hamiltonian Monte Carlo (a.k.a. Hybrid Monte Carlo) – Tingting Zhao's research blog
Pingback: If you did not already know | Data Analytics & R